Uni-ControlNetを触ってみた
Uni-ControlNetを触ってみたのでメモ。
消費VRAM:約21GB
今回モデルになっていただいた男性(フリー素材)

local conditions: Openpose
Prompt: Super Saiyan with rays of light coming from his fingers.

local conditions: Openpose
Prompt: E.T.

local conditions: Openpose
Prompt: Spider man

local conditions: Canny
Prompt: Kabuki actor in kimono

local conditions: Canny
Prompt: Man wearing only underpants

local conditions: Openpose
Prompt: Cute girl with cat ears
無理があった

背景を追加してみる
背景

local conditions: canny
global condition: mlsd
Prompt: Iron man working in a cafe
失敗. 背景はcontentに設定しないといけないらしい.

背景に合うような画像を使ってみる.
local conditions: sketch
global condition: content
Prompt: Robot taking video while walking
自然の背景


カフェの背景

おまけ
local conditions: sketch
global condition: content
prompt: Super wondeful beautiful something

DragGANを触ってみた
以下のリポジトリでDragGAN(非公式実装?)を動かしてみたので作業メモ
インストール
ninjaまわりでエラーが出ていたっぽかったので、ninjaをrepositoryからビルドし、必要なファイルを全てプロジェクトフォルダにコピー - cudaはインストールされていたが、nvccがインストールされていないという状況(原因は不明) 。cuda-toolkitを再インストールして
which nvccで場所を突き止め、/usr/binの中にあることがわかったので無理矢理/usr/local/cuda-11にbinフォルダを作成してnvccをコピー。
ModuleNotFoundError: No module named 'skimage'のエラーがでたのでpip install scikit-imageでインストールModuleNotFoundError: No module named 'IPython'のエラーが出たためpip install IPythonでインストール- 動いた
色々遊んでみた 下の画像ではアヒル口を作ろうとしたが、なぜか突然眼鏡が現れた。

使っているGPUはV100。 GPUのメモリは8G(/32G)くらい使われていて、速度としては1フレームあたり20秒くらい。 ポイントは複数箇所設定できるが、表情の変化と顔の向きの両方を試したところ顔の向きは変化しなかった。 時間があるときにもう少し遊んでみたい。
以上。
Kubernetesチュートリアル
Kubernetesのチュートリアルを動かした際の作業メモ。
本記事で使用している画像は全てkubernetesチュートリアルページからの引用です。
Module1: クラスターの作成
# クラスタの情報取得 kubectl cluster-info
Module2: アプリケーションのデプロイ
# deploymentを作成 kubectl create deployment kubernetes-bootcamp --image=gcr.io/google-samples/kubernetes-bootcamp:v1 # deploymentの一覧を確認 kubectl get deployments # 通信をクラスタ全体のプライベートネットワークに転送するために"proxy"を作成 kubectl proxy # クラスタのバージョン取得 curl http://localhost:8001/version
APIサーバーは、pod名に基づいて各podのエンドポイントを自動的に作成し、プロキシを通じてアクセスできるようにしてくれる。
export POD_NAME=$(kubectl get pods -o go-template --template '{{range .items}}{{.metadata.name}}{{"\n"}}{{end}}')
echo Name of the Pod: $POD_NAME
curl http://localhost:8001/api/v1/namespaces/default/pods/$POD_NAME/
Module3: Podとノードについて
Pod:論理ホスト. 独立したネットワークで動いている. Node: ワーカーマシン(アプリを実行するためのコンピュータリソース). クラスターによって仮想、物理マシンのどちらであってもよい.
podの状態を確認する
# podsの情報を取得 kubectl get pods # podsの中でどんなコンテナが動いているかを確認 kubectl desctibe pods # アプリケーションの出力を確認 curl http://localhost:8001/api/v1/namespaces/default/pods/$POD_NAME/proxy/ # log取得 kubectl logs $POD_NAME # コンテナ上でコマンドを実行 kubectl exec $POD_NAME -- env # bash sessionを実行 kubectl exec -ti $POD_NAME -- bash
Module4: Serviceを使ったアプリケーションの公開
Clusterを使ってコンテナを外部に公開することができる. Clusterは以下の4種類ある.
ClusterIP (既定値) - クラスター内の内部IPでServiceを公開します。この型では、Serviceはクラスター内からのみ到達可能になります。 NodePort - NATを使用して、クラスター内の選択された各ノードの同じポートにServiceを公開します。
: を使用してクラスターの外部からServiceにアクセスできるようにします。これはClusterIPのスーパーセットです。 LoadBalancer - 現在のクラウドに外部ロードバランサを作成し(サポートされている場合)、Serviceに固定の外部IPを割り当てます。これはNodePortのスーパーセットです。 ExternalName - 仕様のexternalNameで指定した名前のCNAMEレコードを返すことによって、任意の名前を使ってServiceを公開します。プロキシは使用されません。このタイプはv1.7以上のkube-dnsを必要とします。
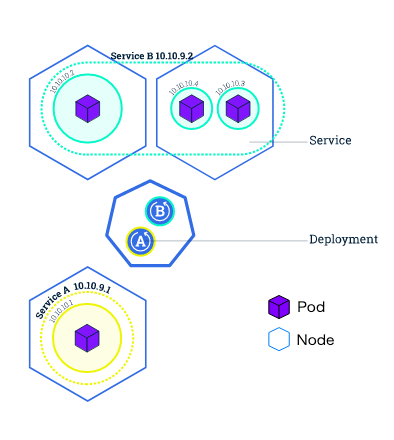
Serviceは、ラベルとセレクタを使用して一連のPodを照合する. ラベルは、作成時またはそれ以降にオブジェクトにアタッチでき、いつでも変更可能.
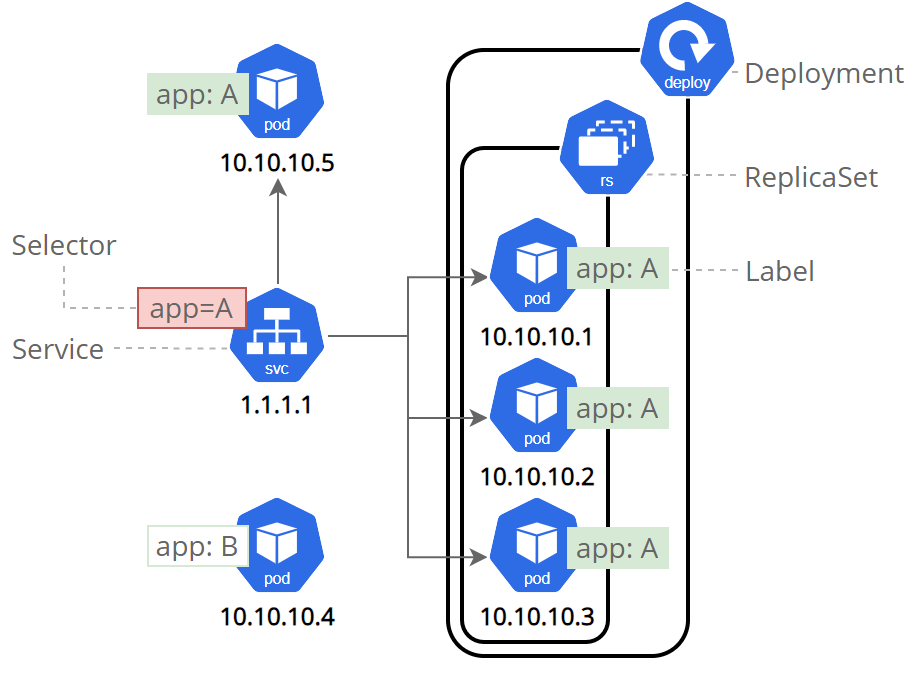
# clusterの情報を確認
kubectl get services
# どのポートが外部に公開されているか確認
kubectl describe services/kubernetes-bootcamp
# 外向けに公開
ubectl expose deployment/kubernetes-bootcamp --type="NodePort" --port 8080
kubectl get services
# node port確認
export NODE_PORT=$(kubectl get services/kubernetes-bootcamp -o go-template='{{(index .spec.ports 0).nodePort}}')
echo NODE_PORT=$NODE_PORT
# リクエスト
curl $(minikube ip):$NODE_PORT
ラベルの付与
# ラベル確認 kubectl describe deployment # ラベルで取得 kubectl get pods -l app=kubernetes-bootcamp kubectl get services -l app=kubernetes-bootcamp # 新しいラベル付与 kubectl label pods $POD_NAME version=v1
サービスの削除
kubectl delete service -l app=kubernetes-bootcamp

Module5: アプリケーションの複数インスタンスを実行
Deploymentをスケールアウトすると新しいPodが作成され、使用可能なリソースを持つノードに割り当てられる.
# Developmentにより作成されたReplicaSetを取得 kubectl get rs # Developmentを4レプリカにスケール kubectl scale deployments/kubernetes-bootcamp --replicas=4 # Developmentを取得 kubectl get deployments


# podsを取得 kubectl get pods -o wide

ロードバランスされているか確認
# service再作成 ubectl expose deployment/kubernetes-bootcamp --type="NodePort" --port 8080 うまくできないので一旦スキップ
スケールダウン
kubectl scale deployments/kubernetes-bootcamp --replicas=2
Module6: ローリングアップデートの実行
ローリングアップデートでは、Podインスタンスを新しいインスタンスで段階的にアップデートすることで、ダウンタイムなしでDeploymentをアップデートできる. Deploymentがパブリックに公開されている場合、Serviceはアップデート中に利用可能なPodのみにトラフィックを負荷分散してくれる。
kubectl get pods # imageのバージョンアップデート kubectl set image deployments/kubernetes-bootcamp kubernetes-bootcamp=jocatalin/kubernetes-bootcamp:v2
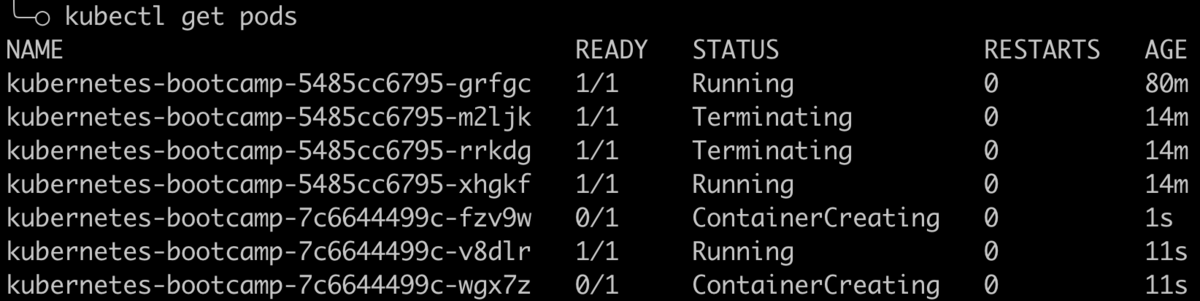
# ロールアウト kubectl rollout status deployments/kubernetes-bootcam # ロールバック kubectl rollout undo deployments/kubernetes-bootcamp
pytorchのDataLoaderについて
kaggleでよく目にする「DataLoader」の役割がよくわからなかったので調べ直しました。 以下ページを参考に(マルパクリして)実装しました。
DataSetとDataLoaderを用いることで、ミニバッチ化を簡単に実装できる!そうです。
DataSet:元々のデータを全て持っていて、ある番号を指定されるとその番号の入出力のペアを返す。クラスを使って実装。
DataLoader:DataSetのインスタンスを渡すことで、ミニバッチ化した後のデータを返す。元から用意されている関数を呼び出す。
DataSetの実装
class DataSet:
def __init__(self):
self.X = [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
self.t = [0, 1, 0, 1, 0, 1, 0, 1, 0, 1]
def __len__(self.X)
def __getitem__(self, index):
return self.X[index], self,t[index]
以上がDataSetの実装。どのように振る舞うかというと
dataset = DataSet() len(dataset) # 10 len(dataset[4]) # (4, 0) len(dataset[2:5]) # ([2, 3, 4], [1, 0, 1])
上記の通りインデックスを指定するとデータとターゲットを返してくれる。
DataLoaderの実装
pytorchのモジュールに含まれるtorch.utils.data.DataLoader()を使う。
dataset = DataSet()
dataloader = torch.utils.data.DataLoader(dataset, batch_size=2, shuffle=True)
for data in dataloader:
print(data)
'''
出力:
[tensor([4, 1]), tensor([0, 1])]
[tensor([0, 7]), tensor([0, 1])]
[tensor([9, 3]), tensor([1, 1])]
[tensor([6, 5]), tensor([0, 1])]
[tensor([8, 2]), tensor([0, 0])]
'''
batch_sizeでバッチサイズを指定し、shuffle=Trueとすることで順番がバラバラになる。
まとめ
DataLoaderの意義と実装方法がなんとなく分かったので、ぜひ使っていきたいと思います。
Microsoft Malware Prediction
Kaggleのコンペの1つ「Microsoft Malware Prediction」のカーネルまとめ
CVとLBの点数に隔たりがある理由について解説しているカーネル。
原因は、TRAINデータとTESTデータでそれぞれ別の分布から引っ張ってきているから。具体的には、TRAINデータは2018年の8,9月のデータであるのに対し、Public TESTは10月、Private TESTは11月のデータ。検証のためにそれぞれのデータの分布を可視化し、TRAINデータを時系列Validationした場合の分布がランダムでValidationをした時に比べてTESTデータの分布に近いことを示している。
モデル1(ランダムValidation)とモデル2(時系列Validation)について、Adversarial Validationの手法を使ってそれぞれを区別できるかどうかを検証。モデル1では区別できる(テストデータと違いがある)が、モデル2ではできないことを実証。
最後に、TrainとPublic Testで違いが大きい説明変数を挙げ、より正確なValidationモデルを作るために分布がTestデータからずれているデータを、Testデータと分布が近い新しい値に変換する必要があると述べている。
TrainデータとTestデータがどちらもサイズが大きい。これを解決する方法を解説するカーネル。
データがアップスケールされて無駄にスペース(メモリ)を消費していないかチェックする。チェックする際にはすべてのデータを読み込む必要はなく、pd.read_csvのchunksizeを使うとよい(参考:pandas でメモリに乗らない 大容量ファイルを上手に扱う - StatsFragments)。
データ読み込みのコツは、 ①オブジェクトデータをカテゴリ変数として読み込む ②バイナリはint8指定 ③欠損値があるバイナリはfloat16に変換(intはnanを読み取れないため) ④64bitのエンコーディングはなるべく32,16bitへ変換する。 これらはread_csvのdatatypesを指定することで実現できる。